������һ��Webϵͳ���շ�����10����������1000����������1�ڵĹ����У�Webϵͳ���ܵ�ѹ����Խ��Խ������������У����ǻ������ܶ�����⡣Ϊ�˽����Щ����ѹ���������⣬������Ҫ��Webϵͳ�ܹ����������εĻ�����ơ��ڲ�ͬ��ѹ���Σ����ǻ�������ͬ�����⣬ͨ�����ͬ�ķ���ͼܹ��������
Web���ؾ���
����Web���ؾ��⣨Load Balancing������˵���Ǹ����ǵķ�������Ⱥ���䡰��������������ǡ���ķ��䷽ʽ�����ڱ������ں�˵�Web��������˵���dz���Ҫ��
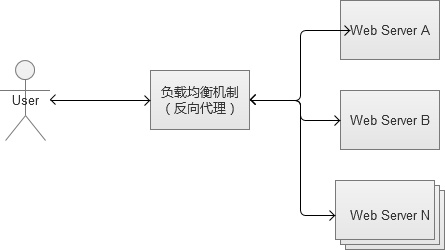
�������ؾ���IJ����кܶ࣬���ǴӼĽ������
����1. HTTP�ض���
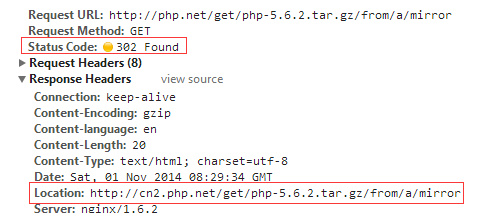
�������û����������ʱ��Web������ͨ����HTTP��Ӧͷ�е�Location���������һ���µ�url��Ȼ��������ټ������������url��ʵ���Ͼ���ҳ���ض���ͨ���ض������ﵽ�����ؾ��⡱��Ŀ�ꡣ���磬����������PHPԴ�����ʱ�����������ʱ��Ϊ�˽����ͬ���Һ͵��������ٶȵ����⣬���᷵��һ�������ǽ������ص�ַ���ض����HTTP��������302������ͼ��
�����ڼ�Webϵͳ������������ֲ�ʽ��Ⱥ �C hansionxu �C ���������
�������ʹ��PHP������ʵ��������ܣ���ʽ���£�

��������ض���dz�����ʵ�֣����ҿ����Զ�����ֲ��ԡ����ǣ����ڴ��ģ�������£����ܲ��ѡ����ң����û�������Ҳ���ã�ʵ���������ض���������������ʱ��
����2. ����������ؾ���
���������������ĺ��Ĺ�����Ҫ��ת��HTTP��������������˺ͺ�̨Web��������ת�Ľ�ɫ����Ϊ��������HTTP�㣨Ӧ�ò㣩��Ҳ���������߲�ṹ�еĵ��߲㣬���Ҳ����Ϊ���߲㸺�ؾ��⡱����������������������ܶ࣬�Ƚϳ�����һ����Nginx��
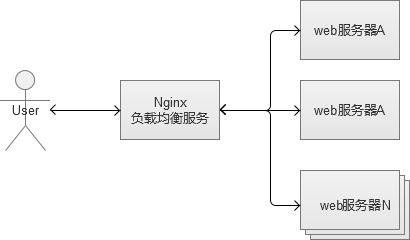
����Nginx��һ�ַdz����ķ�������������������ɶ��ƻ�ת�����ԣ����������������Ȩ�صȡ���������У�������һ�����⣬����Web�������洢��session���ݣ���Ϊһ�㸺�ؾ���IJ��Զ��������������ġ�ͬһ����¼�û�����������֤һ�����䵽��ͬ��Web�����ϣ��ᵼ�����ҵ�session�����⡣
�������������Ҫ�����֣�
- ���÷��������ת��������ͬһ���û�������һ���䵽ͬһ̨�����ϣ�ͨ������cookie�������ӵ�ת���������ĸ����CPU��Ҳ�����˴����������ĸ�����
- ��session�������Ϣ��ר����ij�������������洢������redis/memchache����������DZȽ��Ƽ��ġ�
���������������Ҳ�ǿ��Կ�������ģ���������ˣ������ӷ�������ĸ�������Ҫ����ʹ�á����ָ��ؾ������ʵ�ֺͲ���dz����������ܱ���Ҳ�ȽϺá����ǣ����С�������ϡ������⣬������ˣ�������ܶ���鷳�����ң����˺���Web�������������ӣ����������ܳ�Ϊϵͳ��ƿ����
����3. IP���ؾ���
����IP���ؾ�������ǹ���������㣨��IP���ʹ���㣨�Ķ˿ڣ����IJ㣩����������Ӧ�ò㣨���߲㣩����Ҫ�߳��dz��ࡣԭ���ǣ����Ƕ�IP������ݰ���IP��ַ�Ͷ˿���Ϣ�����ģ��ﵽ���ؾ����Ŀ�ġ����ַ�ʽ��Ҳ����Ϊ���IJ㸺�ؾ��⡱�������ĸ��ؾ��ⷽʽ����LVS��Linux Virtual Server��Linux�������ͨ��IPVS��IP Virtual Server��IP���������ʵ�֡�
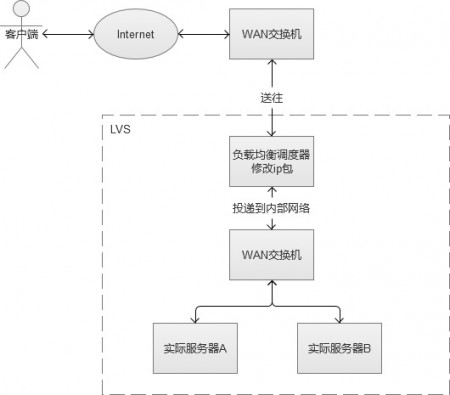
�����ڸ��ؾ���������յ��ͻ��˵�IP����ʱ����IP����Ŀ��IP��ַ��˿ڣ�Ȼ��ԭ�ⲻ����Ͷ�ݵ��ڲ������У����ݰ������뵽ʵ��Web��������ʵ�ʷ�����������ɺ��ֻὫ���ݰ�Ͷ�ݻظ����ؾ����������������Ŀ��IP��ַΪ�û�IP��ַ�����ջص��ͻ��ˡ�
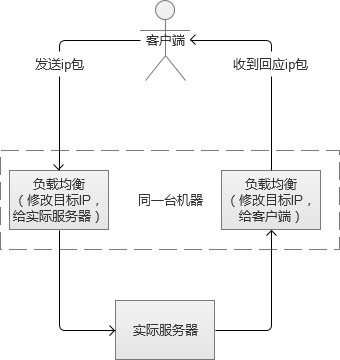
���������ķ�ʽ��LVS-NAT������֮�⣬����LVS-RD��ֱ��·�ɣ���LVS-TUN��IP������������֮�䶼����LVS�ķ�ʽ��������һ��������ƪ�����⣬����
����IP���ؾ��������Ҫ�߳�Nginx�ķ�������ܶ࣬��ֻ�����������Ϊֹ�����ݰ�����������һ���������Ȼ��ֱ��ת����ʵ�ʷ��������������������úʹ�Ƚϸ��ӡ�
����4. DNS���ؾ���
����DNS��Domain Name System���������������ķ�������urlʵ�����Ƿ������ı�����ʵ��ӳ����һ��IP��ַ���������̣�����DNS���������IP��ӳ�䡣��һ�������ǿ������óɶ�Ӧ���IP�ġ���ˣ�DNSҲ�Ϳ�����Ϊ���ؾ������

�������ָ��ؾ�����ԣ����ü����ܼ��ѡ����ǣ��������ɶ�������ң������ӳ���IP����������ʱ���鷳��������DNS��Ч�ӳٵ����⡣
����5. DNS/GSLB���ؾ���
�������dz��õ�CDN��Content Delivery Network�����ݷַ����磩ʵ�ַ�ʽ����ʵ������ͬһ������ӳ��Ϊ��IP�Ļ����ϸ���һ����ͨ��GSLB��Global Server Load Balance��ȫ�ָ��ؾ��⣩����ָ������ӳ��������IP��һ������¶��ǰ��յ���λ�ã������û�����IP���ظ��û����������紫���е�·�ɽڵ�֮�����Ծ���ġ�
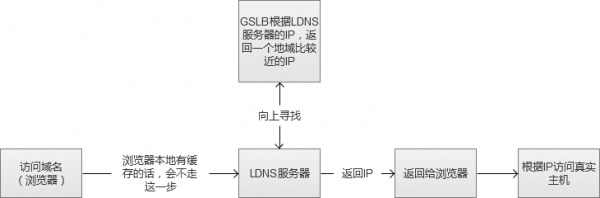
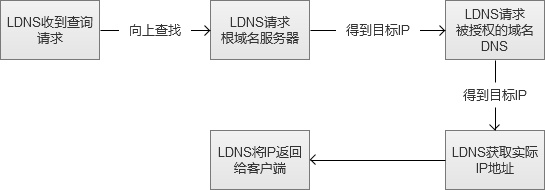
����ͼ�еġ�����Ѱ�ҡ���ʵ�ʹ�����LDNS��Local DNS���������������Root Name Server����ȡ����������Name Server������.com�ģ���Ȼ��õ�ָ����������ȨDNS��Ȼ���ٻ��ʵ�ʷ�����IP��
����CDN��Webϵͳ�У�һ������������������С�ϴ�ľ�̬��Դ��html/Js/Css/ͼƬ�ȣ��ļ������⣬����Щ�Ƚ������������ص����ݣ����������û������������û����顣
�������磬�ҷ�����һ��imgcache.gtimg.cn�ϵ�ͼƬ����Ѷ���Խ�CDN����ʹ��qq.com������ԭ���Ƿ�ֹhttp�����ʱ�����˶����cookie��Ϣ�����һ�õ�IP��183.60.217.90��

�������ַ�ʽ����ǰ���DNS���ؾ���һ�����������ܼ��ѣ�����֧�����ö��ֲ��ԡ����ǣ����ά���ɱ��dz��ߡ�������һ�߹�˾�����Խ�CDN������С��˾һ��ʹ�õ������ṩ��CDN��
Webϵͳ�Ļ�����ƵĽ������Ż�
�����ո����ǽ�����Webϵͳ���ⲿ���绷�����������ǿ�ʼ��ע����Webϵͳ�������������⡣���ǵ�Webվ�����ŷ��������������������ܶ����ս�������Щ���ⲻ���������ݻ�����ô��������ʹ�ú��ʵĻ�����Ʋ��Ǹ�����
�����ʼ�����ǵ�Webϵͳ�ܹ������������ģ�ÿ�����ڣ�������ֻ��1̨������

�������Ǵ�����������ݴ洢��ʼ������
����һ�� MySQL���ݿ��ڲ�����ʹ��
����MySQL�Ļ�����ƣ��ʹ��ȴ�MySQL�ڲ���ʼ����������ݽ��������InnoDB�洢����Ϊ����
����1. ����ǡ��������
��������ǽ��������������ڱ����ݱȽϴ��ʱ�����ټ������ݵ����ã����dzɱ�Ҳ���еġ����ȣ�ռ����һ���Ĵ��̿ռ䣬�������������ͻ����ʹ����Ҫ�������������������������Դ���ݸ�����Σ���������֮�������insert/update/delete�Ȳ�������Ϊ��Ҫ����ԭ������������ʱ�����ӡ���Ȼ��ʵ�������ǵ�ϵͳ��������˵������select��ѯ�����Ӷ࣬��ˣ�������ʹ����Ȼ��ϵͳ�����д�����������á�
����2. ���ݿ������̳߳ػ���
���������ÿһ�����ݿ����������Ҫ�������������ӵĻ��������ݿ���˵������Ҳ��һ�־�Ŀ�����Ϊ�˼��������͵Ŀ�����������MySQL������thread_cache_size����ʾ���������߳����ڸ��á��̲߳�����ʱ���ٴ��������й����ʱ�������١�

������ʵ�����и�Ϊ����һ���������ʹ��pconnect�����ݿⳤ���ӣ����߳�һ�������ںܳ�ʱ���ڶ������š����ǣ��ڷ������Ƚϴ����Ƚ϶������£������÷��ܿ��ܻᵼ�¡����ݿ��������ľ�������Ϊ�������Ӳ������գ����մﵽ���ݿ��max_connections�����������������ˣ������ӵ��÷�ͨ����Ҫ��CGI��MySQL֮��ʵ��һ�������ӳء�������CGI������äĿ��������������
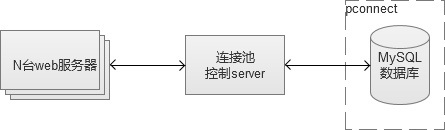
�����������ݿ����ӳط����кܶ�ʵ�ֵķ�ʽ��PHP�Ļ������Ƽ�ʹ��swoole��PHP��һ������ͨѶ��չ����ʵ�֡�
����3. Innodb�������ã�innodb_buffer_pool_size��
����innodb_buffer_pool_size���Ǹ������������������ݵ��ڴ滺���������������MySQL��ռ�Ļ�����һ���Ƽ�Ϊ���������ڴ��80%����ȡ�����ݵij����У������Լ��ٴ���IO��һ����˵�����ֵ����Խ��cache�����ʻ�Խ�ߡ�
����4. �ֿ�/�ֱ�/������
����MySQL���ݿ��һ������������ڰ����������������������ܽ�����ִ�����½�����ˣ�������Ԥ���������ᳬ�����������ʱ������зֿ�/�ֱ�/�����Ȳ�������õ��������Ƿ����ڴ֮�������Ϊ�ֿ�ֱ��Ĵ洢ģʽ���Ӹ����϶ž��к��ڵķ��ա�������������һЩ�����ԣ������б�ʽ�IJ�ѯ��ͬʱ��Ҳ������ά���ĸ��Ӷȡ�����������������ǧ��������ϵ�ʱ�����ǻᷢ�֣����Ƕ���ֵ�õġ�
�������� MySQL���ݿ��̨����
����1̨MySQL������ʵ�����Ǹ߷��յĵ��㣬��Ϊ��������ˣ�����Web����Ͳ������ˡ����ң�����Webϵͳ�������������ӣ�������һ�죬���Ƿ���1̨MySQL��������֧����ȥ�����ǿ�ʼ��Ҫʹ�ø����MySQL�������������̨MySQL������ʱ�ܶ��µ������ֽ�������
����1. ����MySQL���ӣ��ӿ���Ϊ����
����������������Ϊ�˽����������ϡ������⣬����������ϵ�ʱ���л����ӿ⡣��������������ʵ�����е��˷���Դ����Ϊ�ӿ�ʵ���ϱ������ˡ�
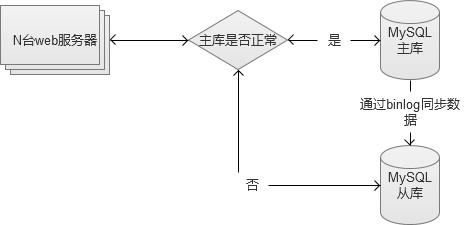
����2. MySQL��д���룬����д���ӿ����
������̨���ݿ�����д���룬���⸺��д����IJ������ӿ⸺����IJ��������ң�������ⷢ�����ϣ���Ȼ��Ӱ����IJ�����ͬʱҲ���Խ�ȫ����д����ʱ�л����ӿ��У���Ҫע�����������ܻ���Ϊ�������Ѵӿ�Ҳ�Ͽ壩��

����3. ����������
������̨MySQL֮�以Ϊ�˴˵Ĵӿ⣬ͬʱ�������⡣���ַ������������˷�������ѹ��������ͬʱҲ����ˡ�������ϡ����⡣�κ�һ̨���ϣ�����������һ�ɹ�ʹ�õķ���
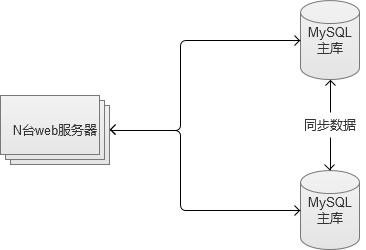
�������������ַ�����ֻ��������̨�����ij��������ҵ����չ���Ǻܿ�Ļ�������ѡ��ҵ����룬�����������������
�������� MySQL���ݿ����֮�������ͬ��
����ÿ�����ǽ��һ�����⣬�µ������Ȼ�����ھɵĽ�������ϡ��������ж�̨MySQL����ҵ��߷��ڣ��ܿ��ܳ���������֮����������ӳٵij��������ң�����ͻ������صȣ�Ҳ��Ӱ������ͬ�����ӳ١��������������������շ������ӽ�1�ڵ����ⳡ���£����֣��ӿ�������Ҫ�ܶ������ͬ������������ݡ����ֳ����£��ӿ����ʧȥЧ���ˡ�
�������ǣ����ͬ�����⣬����������һ����Ҫ��ע�ĵ㡣
����1. MySQL�Դ����߳�ͬ��
����MySQL5.6��ʼ֧������ʹӿ�����ͬ�����߶��̡߳����ǣ�����Ҳ�DZȽ����Եģ�ֻ���Կ�Ϊ��λ��MySQL����ͬ����ͨ��binlog��־������д�뵽binlog��־�IJ������Ǿ���˳��ģ����䵱SQL�����к��ж��ڱ��ṹ���ĵȲ��������ں�����SQL����������Ӱ��ġ���ˣ��ӿ�ͬ�����ݣ������ߵ����̡�
����2. �Լ�ʵ�ֽ���binlog�����߳�д�롣
���������ݿ�ı�Ϊ��λ������binlog���ű�ͬʱ������ͬ�����������Ļ�����ȷ�ܹ��ӿ�����ͬ����Ч�ʣ����ǣ�������ͱ�֮����ڽṹ��ϵ�������������Ļ�����ͬ������д��˳������⡣���ַ�ʽ��������һЩ�Ƚ��ȶ�������Զ��������ݱ���
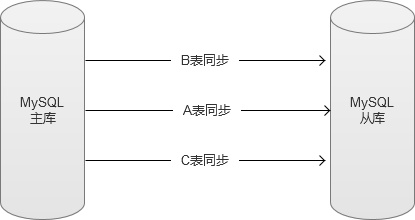
��������һ��������˾���ֶ���ͨ�����ַ�ʽ�����ӿ�����ͬ��Ч�ʡ����и�Ϊ��������������ֱ�ӽ���binlog�������Ա�Ϊ��λ��ֱ��д�롣��������������ʵ�ָ��ӣ�ʹ�÷�Χ���ܵ����ƣ�ֻ������һЩ������������ݿ��У�û�б��ṹ��������ͱ�֮��û���������������������
�����ġ� ��Web�����������ݿ�֮�佨������
����ʵ���ϣ����������������⣬���ܽ������������ݿ���档���ݡ����˶��ɡ���80%������ֻ��ע��20%���ȵ������ϡ���ˣ�����Ӧ�ý���Web�����������ݿ�֮��Ļ�����ơ����ֻ��ƣ������ô�����Ϊ���棬Ҳ�������ڴ滺��ķ�ʽ��ͨ�����ǣ����ֵ��ȵ����ݲ�ѯ���赲�����ݿ�֮ǰ��

����1. ҳ�澲̬��
�����û�������վ��ij��ҳ�棬ҳ���ϵĴ������ںܳ�һ��ʱ���ڣ����ܶ���û�б仯�ġ�����һƪ���ű�����һ�����������Dz��������ݵġ������Ļ���ͨ��CGI���ɵľ�̬htmlҳ�滺�浽Web�������Ĵ��̱��ء����˵�һ�Σ���ͨ����̬CGI��ѯ���ݿ��ȡ֮�⣬֮��ֱ�ӽ����ش����ļ����ظ��û���
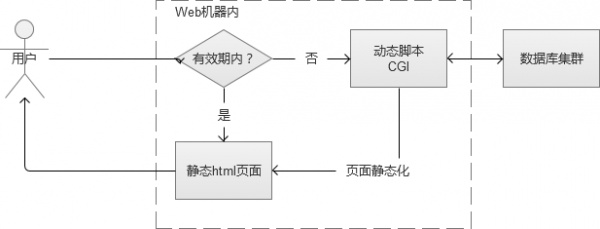
������Webϵͳ��ģ�Ƚ�С��ʱ�����������������������ǣ�һ��Webϵͳ��ģ������統����100̨��Web��������ʱ��������Щ�����ļ���������100�ݣ��������Դ�˷ѣ�Ҳ����ά�������ʱ�����˻��룬���Լ���һ̨���������������Ǻǣ����翴������һ�ֻ��淽ʽ�ɣ��������������ġ�
����2. ��̨�ڴ滺��
����ͨ��ҳ�澲̬���������У����ǿ���֪���������桱���Web���������Dz���ά���ģ�������������⣨ʵ���ϣ�ͨ��PHP��apc��չ����ͨ��Key/value����Web�������ı����ڴ棩����ˣ�����ѡ�����ڴ滺�����Ҳ������һ�������ķ���
�����ڴ滺���ѡ����Ҫ��redis/memcache����������˵�����߲�ӹ��ܷḻ�̶���˵��Redis��ʤһ�
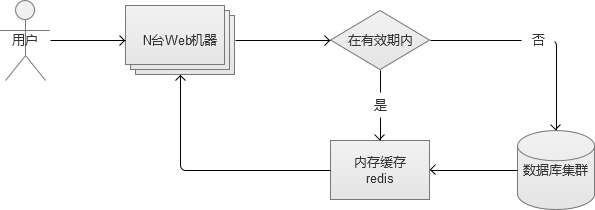
����3. �ڴ滺�漯Ⱥ
���������Ǵ��̨�ڴ滺����ϣ������ֻ����ٵ�����ϵ����⣬��ˣ����DZ��뽫�����һ����Ⱥ�����������Ǹ�������һ��slave��Ϊ���ݻ��������ǣ������������ĺܶ࣬���Ƿ���cache�����ʲ��ߣ���Ҫ����Ļ����ڴ��أ���ˣ����Ǹ����齫�����ó�һ����Ⱥ�����磬����redis cluster��
����Redis cluster��Ⱥ�ڵ�Redis��Ϊ�������ӣ�ͬʱÿ���ڵ㶼���Խ�����������չ��Ⱥ��ʱ��ȽϷ��㡣�ͻ��˿���������һ���ڵ㷢��������������ġ����𡱵����ݣ���ֱ�ӷ������ݡ�������ʵ�ʸ���Redis�ڵ㣬Ȼ��ַ��֪�ͻ��ˣ��ͻ�����������

��������ʹ�û������Ŀͻ�����˵����һ�������ġ�

�����ڴ滺��������л���ʱ������һ�����յġ���A��Ⱥ�л���B��Ⱥ�Ĺ����У����뱣֤B��Ⱥ��ǰ���á�Ԥ�ȡ���B��Ⱥ���ڴ��е��ȵ����ݣ�Ӧ�þ�����A��Ⱥ��ͬ�������л���һ˲������������ݣ���B��Ⱥ���ڴ滺���в��Ҳ���������ֱ�ӳ����˵����ݿ���ܿ��ܵ������ݿ�崻�����
����4. �������ݿ⡰д��
��������Ļ��ƣ���ʵ�ּ������ݿ�ġ������IJ��������ǣ�д�IJ���Ҳ��һ�����ѹ����д�IJ�������Ȼ�����٣����ǿ���ͨ���ϲ�����������ѹ����Ч�������ʱ�����Ǿ���Ҫ���ڴ滺�漯Ⱥ�����ݿ⼯Ⱥ֮�䣬����һ����ͬ�����ơ�
�����Ƚ���������Ч��cache�У�������ѯ��ʾ������Ȼ����Щsql�ķ��뵽һ�������д洢����������������ÿ��һ��ʱ�䣬�ϲ�Ϊһ���������ݿ��и������ݿ⡣

������������ͨ���ı�ϵͳ�ܹ��ķ�ʽ����д�������⣬MySQL����Ҳ����ͨ�����ò���innodb_flush_log_at_trx_commit������д����̵IJ��ԡ���������ɱ���������Ӳ�����������⣬����ѡ����һ���RAID��Redundant Arrays of independent Disks�����������߱Ƚ��µ�SSD��Solid State Drives����̬Ӳ�̣���
����5. NoSQL�洢
�����������ݿ�Ķ�����д���������ٽ�һ�����ǣ��ջ�ﵽ����������ʱ���ij����������ӻ����ijɱ��Ƚϸߣ����Ҳ�һ������������������ʱ�����ʱ���ֺ������ݣ��Ϳ��Կ���ʹ��NoSQL�����ݿ⡣NoSQL�洢���ֶ��Dz���key-value�ķ�ʽ������Ƚ��Ƽ�ʹ��������ܹ�Redis��Redis������һ���ڴ�cache��ͬʱҲ���Ե���һ���洢��ʹ�ã�����ֱ�ӽ�������ص����̡�
���������Ļ������Ǿͽ����ݿ���ijЩ��Ƶ����д�����ݣ�������������������´��Redis�洢��Ⱥ�У��ֽ�һ������ԭ��MySQL���ݿ��ѹ����ͬʱ��ΪRedis�����Ǹ��ڴ漶���Cache����д�����ܶ�������������

��������һ��������˾���ܹ��ϲ��õĽ�������ܶ�������������������������ʹ�õ�cache����ȴ��һ����Redis�����ǻ��и��ḻ������ѡ��������������ҵ���ص㿪�����Լ���NoSQL����
����6. �սڵ��ѯ����
���������Ǵ��ǰ����˵��ȫ��������ΪWebϵͳ�Ѿ���ǿ��ʱ�����ǻ����Ǿ仰���µ�����ǻ����ġ��սڵ��ѯ����ָ��Щ���ݿ��и��������ڵ������������磬�������ѯһ����������Ա��Ϣ��ϵͳ��Ӹ����������ң����鵽�����ݿⱾ����Ȼ��ŵó����Ҳ����Ľ��ۣ����ظ�ǰ�ˡ���Ϊ����cache������Ч����������Ƿdz�����ϵͳ��Դ�ģ�����������Ŀսڵ��ѯ���ǿ��Գ����ϵͳ����ġ�
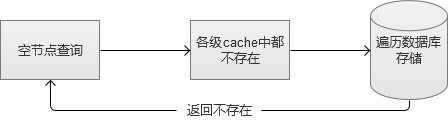
�������������Ĺ��������У��������亦����ˣ�Ϊ��ά��Webϵͳ���ȶ��ԣ�����ʵ��Ŀսڵ���˻��ƣ��dz��б�Ҫ��
�������ǵ�ʱ���õķ�ʽ���������һ�żļ�¼ӳ����������ڵļ�¼�洢���������뵽һ̨�ڴ�cache�У������Ļ���������пսڵ��ѯ�����ڻ�����һ��ͱ��赲�ˡ�

��ز��𣨵����ֲ�ʽ��
��������������ܹ�����֮�����ǵ�ϵͳ�Ƿ���Ѿ��㹻ǿ�����أ��𰸵�Ȼ�ǷĹ����Ż������ġ�Webϵͳ��Ȼ�����Ͽ����ƺ��Ƚ�ǿ���ˣ����Ǹ����û�������ȴ��һ������õġ���Ϊ������ͬѧ���������ڵ�һ����վ���������ǻ�е�һЩ��������ϵ��������ʱ�����Ǿ���Ҫ����ز�����Webϵͳ���û�������
����һ�� ���ļ�����ڵ��ɢ
����������������ε�ͬѧ����֪�����������кܶ�����ģ�һ�㶼�ǰ��յ������֣�����㶫ר��������ר�������һ���ڹ㶫����ң�ȥ����ר���棬��ô����о����Ա��ڹ㶫ר������ʵ���ϣ���Щ���������ƾ��Ѿ�˵���ˣ����ķ��������ڵأ����ԣ��㶫�����ȥ���ӵش������ķ����������統Ȼ��Ƚ�����
������һ��ϵͳ�ͷ����㹻���ʱ�ͱ��뿪ʼ������ز���������ˡ�����ķ����������û�����������ǰ���Ѿ��ᵽ��Web�ľ�̬��Դ�����Դ����CDN�ϣ�Ȼ��ͨ��DNS/GSLB�ķ�ʽ���þ�̬��Դ�ķ�ɢ��ȫ�����ء������ǣ�CDNֻ����ľ�̬��Դ�����⣬û�н������Ӵ��ϵͳ����ֻ������ij���̶����е����⡣
�������ʱ����ز���Ϳ�ʼ�ˡ���ز���һ����ѭ�����ļ��У��ڵ��ɢ��
- ���ļ��У�ʵ�ʲ�������У�����һ���ֵ����ݺͷ�����ڲ��ɲ�����ף����߲�����׳ɱ���������Щ��������ݣ�����Ȼά��һ�ף�������ص�ѡ��һ������Ƚ����ĵĵط���ͨ�������ڲ�ר���������ڵ�ͨѶ��
- �ڵ��ɢ����һЩ������Ϊ���ף��ֲ��ڸ������нڵ㣬���û�������ѡ����Ľڵ���ʷ���
�������磬����ѡ�����Ϻ�����Ϊ���Ľڵ㣬���������ڣ��人���Ϻ�Ϊ��ɢ�ڵ㣨�Ϻ��Լ�����Ҳ��һ����ɢ�ڵ㣩�����ǵķ���ܹ���ͼ��

������Ҫ����һ�µ��ǣ���ͼ���Ϻ��ڵ�ͺ��Ľڵ���ͬ����һ�������ģ�������ɢ�ڵ���Զ���������
�����кܶ�������Σ����Ǵ�����ѭ�����ܹ������ǻ��������������û������˺ŵȷ��ں��Ľڵ㣬���ֵ��������ݣ�����װ������������ݺͷ�����ڵ����ڵ����Ȼ�����Ľڵ�͵���ڵ�֮�䣬Ҳ�л�����ơ�
�������� �ڵ����ֺ��ر���
�����ڵ�������ָ��ij���ڵ������������ʱ��������Ҫ����һ������ȥ��֤������Ȼ���á��������ʣ�����Ƚϳ��������ַ�ʽ�����л����������нڵ㡣����ϵͳ�����ڵ㷢�����ϣ���ô���Ǿͽ����������л��������ı����ڵ��ϡ����ǵ����ؾ��⣬������Ҫͬʱ�������л��������ļ�������ڵ㡣��һ���棬���Ľڵ�����Ҳ����Ҫ�Լ��������ֺͱ��ݵģ����Ľڵ�һ�����ϣ��ͻ�Ӱ��ȫ������
�������ر�����ָ����һ���ڵ��Ѿ��ﵽ����������������ӽ��ܸ��������ˣ�ϵͳ������һ�������Ļ��ơ�һ�������Ѿ������أ������������µ�������ܿ��ܾ���崻���Ӱ�������ڵ�ķ���Ϊ�����ٱ��ϴ��û�������ʹ�ã����ر����DZ�Ҫ�ġ�
����������ر�����һ��2������
- �ܾ�����������֮�Ͳ��ٽ����µ����������������ε����е��Ŷӡ�
- �����������ڵ㡣���ֵĻ���ϵͳʵ�ָ�Ϊ���ӣ����漰�����ؾ�������⡣
��
����Webϵͳ�����ŷ��ʹ�ģ�������������ش�1̨������������������һֱ�ɳ�Ϊ����Ȼ����Ĵ�Ⱥ�������Webϵͳ���Ĺ��̣�ʵ���Ͼ������ǽ������Ĺ��̡��ڲ�ͬ�ĽΣ������ͬ�����⣬���µ������ֵ����ھɵĽ������֮�ϡ�
����ϵͳ���Ż���û�м��ģ�������ϵͳ�ܹ�Ҳһֱ�ڿ��ٷ�չ���µķ���������ϵ����⣬ͬʱҲ�����µ���ս�� |